基于Dirty Frag漏洞发现过程的“攻击原语”思考
——再论漏洞发现与分析工作的人机分工
作者:安天研究院 时间 :2026年05月09日
导语
安天CERT基于对Theori研究员Taeyang Lee借助Xint Code平台发现并曝光Copy Fail(CVE-2026-31431)的相关信息的分析挖掘,撰写了人与AI协同的漏洞分析新范式——Copy Fail发现过程解析》一文。文章指出,在内核漏洞研究从“工匠时代”加速进入“人机协同时代”的过程中,工作范式正在被重构——“人聚焦‘问对问题’,AI负责‘问遍所有相关问题’”。有网友询问:如何理解“问对问题”?我们借助Theori前研究员Hyunwoo Kim(@v4bel)曝光的新重大漏洞Dirty Frag的跟进分析,展开对“问对问题”的理解,并尝试以“攻击原语”为锚点,重构漏洞发现与分析的范式框架。
1.引言
1.1 事件背景:Dirty Frag 漏洞的技术概要与社会化披露冲击
2026年5月,独立安全研究员Hyunwoo Kim(@v4bel)披露了一个影响全系列主流Linux发行版的本地权限提升(LPE)漏洞——Dirty Frag (CVE-2026-43284,CVE-2026-43500)。Dirty Frag的技术本质并非单一漏洞,而是两个页缓存(Page Cache)写入原语的链式组合:根植于IPsec/xfrm子系统的xfrm-ESP Page-Cache Write(2017年1月引入)与根植于RxRPC子系统的RxRPC Page-Cache Write(2023年6月引入)。两者单独利用均存在环境限制,但Hyunwoo Kim通过链式组合实现了跨发行版、跨配置的稳定提权,覆盖Ubuntu 24.04.4、RHEL 10.1、openSUSE Tumbleweed、CentOS Stream 10、AlmaLinux 10、Fedora 44等主流系统。
Dirty Frag的披露在Copy Fail(CVE-2026-31431)曝光后极短时间内出现,两者共享同一攻击哲学——页缓存可控写入(Page-Cache Write Primitive),但Dirty Frag通过跨子系统原语互补,将利用的通用性与可靠性提升至新的高度。这一事件不仅是一次技术层面的漏洞曝光,更对当前的漏洞响应机制、负责任披露流程以及安全研究的人机协同模式提出了深刻挑战。
1.2 问题提出:从“崩溃点发现”到“原语抽象(Primitive)”的认知升级
传统的漏洞研究往往以“发现崩溃点”为起点,以“获得CVE编号”为终点,研究者的注意力集中在触发条件、崩溃现场与补丁差异上。然而,Dirty Frag的发现过程揭示了一种更高阶的研究范式:发现者Hyunwoo Kim并非在寻找“又一个缓冲区溢出”或“又一个UAF”,而是在系统性地狩猎一种稀缺能力——页缓存写入原语。这种范式转换要求研究者从“现象描述”跃迁至“能力抽象”,从关注“哪行代码错了”转向关注“这段代码会赋予了利用者什么原子能力”。
攻击原语(Attack Primitive)是漏洞利用研究中的核心工程概念,指攻击者通过某个漏洞或机制获得的、可被稳定复用的基础操作能力。它不是完整的exploit,而是构成exploit的“原子操作”。理解攻击原语,是区分“漏洞分析研究员”与“漏洞利用工程师”的关键分水岭。
1.3 研究目标:以攻击原语为锚点,重构漏洞发现与分析的范式框架
本报告旨在以Hyunwoo Kim发现Dirty Frag漏洞的过程为解剖样本,解析攻击原语的基本框架与分类体系,解构Dirty Frag的双原语链式结构,透视Hyunwoo Kim从子系统审计到“原语狩猎”的方法论路径,并在此基础上重新论述漏洞发现与分析工作中的人机分工。最终,将尝试回答:在AI辅助漏洞挖掘能力爆发的背景下,人类研究员的核心价值何在(即如何问对问题)?工具链应如何进化?防御体系应如何转型?
1.4 报告范围与术语约定
本报告聚焦Linux内核本地提权场景,核心术语定义如下:
攻击原语(Attack Primitive):可被稳定复用的基础攻击能力单元,如页缓存写入、任意地址读、控制流劫持等。
页缓存写入原语(Page-Cache Write Primitive):在不触碰磁盘文件的前提下,向内存中的页缓存页(page cache page)写入可控数据的能力。
链式组合(Chaining):将多个独立攻击原语按逻辑顺序拼接,以绕过各自的环境限制,构建完整杀伤链。
Dirty家族:指Dirty Pipe(CVE-2022-0847)、Copy Fail(CVE-2026-31431)、Dirty Frag等共享页缓存篡改范式的漏洞谱系。
2. 攻击原语的理论框架与分类体系
2.1 概念界定:从密码学原语到漏洞利用原语的语义迁移
在密码学中,“原语”(Primitive)指哈希、对称加密、签名等基础算法——它们本身不解决具体业务问题,但可通过组合构建出TLS、VPN、区块链等复杂协议。攻击原语借用了这一概念:它是构成漏洞利用的“最小功能单元”。单个原语往往不足以完成致效,但它是支撑完整杀伤链的基础。
从密码学原语到攻击原语的语义迁移,体现了安全研究从“防御性抽象”向“攻击性抽象”的范式扩展。密码学原语回答“我能安全地做什么”,攻击原语回答“我能利用系统做什么”。两者共同遵循组合性(Composability)、确定性(Determinism)与可复用性(Reusability)三大原则。
2.2 内核本地提权(LPE)场景的原语四分法:读、写、执、降级
在Linux内核本地提权研究中,攻击原语可按能力类型分为四类:
| 类型 | 能力描述 | 典型来源 |
| 读原语(Read Primitive) | 读取内核/用户态任意地址数据 | 信息泄漏、侧信道、UAF读 |
| 写原语(Write Primitive) | 向内核/用户态任意地址写入可控数据 | 页缓存篡改、OOB写、UAF写 |
| 执行原语(Execute Primitive) | 劫持控制流(修改函数指针、返回地址) | ROP、JOP、内核UAF |
| 降级原语(Downgrade Primitive) | 绕过安全边界(禁用COW、绕过SELinux) | 逻辑缺陷、配置篡改、引用计数操纵 |
Dirty Frag和Copy Fail提供的正是写原语中最稀缺的一类——页缓存可控写入原语。这类原语的稀缺性在于:它允许攻击者修改内存中setuid二进制文件的页缓存副本,而无需触碰磁盘,从而绕过文件完整性监控与签名验证机制。
2.3 页缓存写入原语(Page-Cache Write Primitive)的特殊地位与稀缺性
页缓存(Page Cache)是Linux内核用于缓存文件系统数据的核心机制。当用户态程序读取文件时,内核将磁盘块映射到内存页缓存页,程序实际读取的是页缓存副本。正常情况下,页缓存页对映射它的用户态进程是只读的;任何写入应触发COW(Copy-On-Write),由内核分配新页并复制数据。
页缓存写入原语的本质是:找到一个内核代码路径,该路径在误认为页缓存页可安全原地修改的情况下,向其写入攻击者可控的数据。这种原语的特殊性在于:
1. 无文件写权限要求:攻击者无需拥有目标文件的写权限,甚至无需拥有所在目录的写权限。
2. 绕过完整性监控:由于仅修改内存中的页缓存,不触发磁盘回写,文件系统级别的完整性检查(如IMA/EVM)无法感知。
3. 高确定性:逻辑漏洞导致的页缓存写入不依赖竞态条件,成功率接近100%。
4. 跨版本稳定性:页缓存机制是内核核心架构,利用方式在不同内核版本间高度稳定。
正因上述特性,页缓存写入原语成为本地提权研究中的“魔戒”级能力。Dirty Pipe首次证明该原语可行,Copy Fail证明其可复现,Dirty Frag则证明其可工程化、通用化。
2.4 攻击原语与经典安全模型的映射:杀伤链、ATT&CK、STRIDE 的互补视角
攻击原语思维可与经典安全模型形成互补映射:
杀伤链(Kill Chain):攻击原语对应杀伤链中的“武器化”(Weaponization)阶段。页缓存写入原语是一种通用武器化组件,可适配不同初始访问向量。
ATT&CK框架:页缓存写入原语映射至T1068(Exploitation for Privilege Escalation),但更细粒度地揭示了“利用机制”而非仅“利用行为”。
STRIDE:从威胁建模视角,页缓存写入原语利用了“篡改”(Tampering)威胁的实例化——但篡改对象从传统意义上的“数据”升级为“执行体在内存中的映像”。
将攻击原语纳入经典模型,有助于防御方从“能力消除”而非仅“漏洞修补”的维度重构防御体系。
3. Dirty Frag 的攻击原语解构
3.1 技术本质:非单一漏洞,而是双原语链式组合结构
Dirty Frag的技术本质必须被准确理解:它不是一个单一commit引入的缺陷,而是两个独立页缓存写入原语的链式组合。Hyunwoo Kim在披露中明确将其定义为“两个Page-Cache Write primitive的链式利用”,这一自我定位揭示了现代漏洞研究的工程化高度——研究者不再仅追求 “发现一个‘完美’的漏洞”,而是追求“一组互补的原语”。
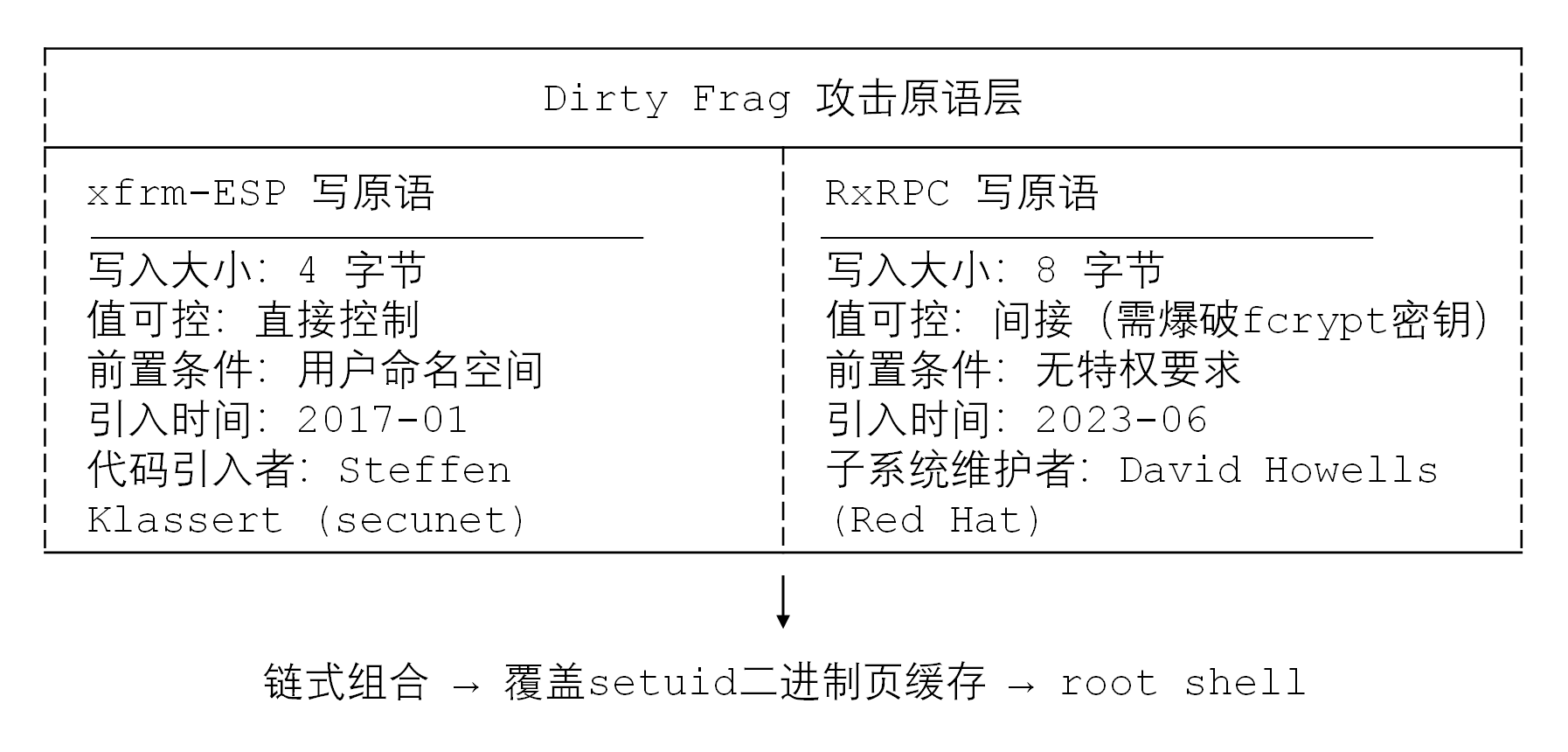
3.2 xfrm-ESP 写原语:4 字节可控写入的能力边界与命名空间约束
xfrm-ESP写原语根植于IPsec/ESP子系统。2017年1月,Steffen Klassert为优化ESP数据路径性能,提交了esp4/6: Avoid skb_cow_data whenever possible,意在减少不必要的COW开销。该优化在ESP输出路径中使用skb_page_frag_refill直接分配页片段,但当通过splice()将外部共享的页缓存页注入skb的frag时,ESP解密路径会原地写入这些共享页。
具体而言,攻击者通过splice()将setuid二进制文件(如/usr/bin/su)的页缓存页映射到管道,再将其作为ESP数据包的一部分送入IPsec栈。ESP解密路径中的esp_input()系列函数在解密ESP尾部时,通过skb_put()或pskb_put()向skb的尾部写入4字节的seq_hi字段——而这一写入直接发生在攻击者注入的页缓存页上。由于seq_hi的值可由攻击者通过构造ESP数据包直接控制,因此实现了4字节完全可控写入。
然而,xfrm-ESP原语存在一个关键限制:需要用户创建网络命名空间。在Ubuntu等默认启用并严格配置AppArmor的发行版中,通过apparmor_restrict_unprivileged_userns等策略,非特权用户创建用户命名空间的能力受到限制,导致该原语单独无法利用。
3.3 RxRPC 写原语:8 字节写入的无特权路径与 fcrypt 密钥爆破机制
RxRPC写原语是Dirty Frag的“第二把钥匙”,其核心价值在于完全不需要任何特权。RxRPC(AF_RXRPC)是Linux内核中用于AFS(Andrew File System)和Kerberos认证的远程过程调用协议。在RxRPC的Kerberos认证路径rxkad_verify_packet_1()中,收到的数据包前8字节会执行原地PCBC(fcrypt)解密:

skb_to_sgvec()直接将skb的frag(包含攻击者通过splice()注入的页缓存页)转换为scatterlist,且src与dst指向同一个sg。因此,解密操作将8字节的“解密结果”写回了只读的页缓存页面。
与xfrm-ESP不同,RxRPC原语的值无法直接控制——它是fcrypt_decrypt(C, K)的结果。攻击者需要先通过add_key("rxrpc", ...)注册一个密钥K,然后在用户态爆破,找到能产出目标8字节明文的那个K。fcrypt是56-bit密钥、8-byte块的AFS专用密码,爆破空间可控。最关键的是:RxRPC路径完全不需要用户命名空间、不需要网络命名空间、不需要CAP_NET_ADMIN。而且Ubuntu默认加载rxrpc.ko模块。
3.4 原语链式互补:从单点缺陷到跨子系统通用提权框架的跃迁
Dirty Frag的突破性在于原语链式互补的工程化设计:
xfrm-ESP原语提供4字节直接可控写入,但受限于命名空间;
RxRPC原语提供8字节间接可控写入,但无任何特权要求。
Hyunwoo Kim的利用链逻辑如下:首先通过RxRPC原语在无特权环境下获得初步写入能力,或通过xfrm-ESP原语在允许命名空间的环境中实现精确写入;两者互补覆盖了所有主流发行版的默认配置。这种“拼接”思路意味着:即使单个原语存在环境限制,攻击者仍可通过跨子系统原语互补实现通用提权。
这是现代漏洞利用的工程化升级:从“单点原语”进化为“多原语链式组合”,从“特定子系统的漏洞”进化为“跨子系统、跨发行版的通用提权框架”。
3.5 “Dirty”家族谱系:Dirty Pipe → Copy Fail → Dirty Frag 的原语继承与能力进化
Dirty Frag、Copy Fail与更早的Dirty Pipe构成一个日益成熟的攻击谱系,三代演进体现了页缓存写入原语的发现、复现与通用化:
| 代际 | 漏洞 | 核心子系统 | 页缓存写入能力 | 标志性意义 |
| 第一代 | Dirty Pipe(CVE-2022-0847) | Pipe子系统 | 首次证明页缓存可篡改 | 开创“Dirty”攻击范式,Max Kellermann发现 |
| 第二代 | Copy Fail(CVE-2026-31431) | AF_ALG加密子系统 | 通过加密操作实现写入 | AI辅助发现,证明范式可复现 |
| 第三代 | Dirty Frag (CVE-2026-43284,CVE-2026-43500) | xfrm-ESP + RxRPC | 双原语链式利用,绕过环境限制 | 通用化、工程化、武器化,Hyunwoo Kim实现 |
三代漏洞发现演进的核心规律:每一代都在证明同一类攻击原语的可行性,但每一代都在子系统选择、环境适配与工程化可靠性上实现跃迁。Dirty Frag被称为Copy Fail的“继任者”(successor),并非说明其存在某种“任务”性的承继关系,而是因为两者提供了同一类攻击原语——页缓存可控写入——而非因为它们利用了相似的代码缺陷。
4. 漏洞发现过程的方法论透视
4.1 研究路径:Hyunwoo Kim 从子系统审计到“原语狩猎”的思维转换
Hyunwoo Kim(@v4bel,金贤宇)是专注于Linux内核的独立漏洞研究者,2022至2025曾就职于韩国安全公司 Theori其比与Copy Fail的发现者Taeyang Lee(李泰阳),更早一年加入Theori。Kim曾获Google kernelCTF奖项与Pwnie Awards 2025最佳提权奖。其研究路径呈现鲜明的范式特征:从子系统功能审计转向攻击原语狩猎。
传统审计路径是:选择一个子系统 → 阅读代码 → 寻找bug → 构造POC。而Kim的路径是:定义目标原语(页缓存写入)→ 枚举所有可能提供该原语的子系统 → 验证每个候选路径的确定性逻辑缺陷。这种思维转换的实质是从“代码中心”转向“能力中心”——代码只是获得原语的途径,原语本身才是研究目标。
在Dirty Frag的发现中,Kim系统性地梳理了内核中所有涉及“原地解密/原地修改”且与页缓存交互的子系统:xfrm-ESP(IPsec)、RxRPC(AFS/Kerberos)、以及可能的其他加密/网络路径。这种“原语狩猎”思维使其能够跨越看似无关的子系统(IPsec与AFS),发现它们共同提供的页缓存写入能力。
4.2 发现逻辑:页缓存篡改攻击面的系统性梳理与确定性逻辑缺陷识别
Dirty Frag的发现逻辑可分解为三个层次:
第一层:攻击面枚举。识别所有内核子系统中满足以下条件的代码路径:
处理来自用户态的数据(如splice()注入的页缓存页);
执行原地写操作(解密、解压缩、头部修改等);
未对共享页执行COW检查。
第二层:确定性逻辑缺陷识别。优先选择不依赖竞态条件的逻辑缺陷。Dirty Frag的两个原语均为确定性逻辑漏洞——不依赖时间窗口,失败不引发内核恐慌,成功率极高。这与传统竞态条件漏洞(如UAF)形成鲜明对比,体现了工程化exploit开发对可靠性的极致追求。
第三层:环境适配验证。单独验证每个原语的环境限制(命名空间要求、模块加载状态、特权需求),然后寻找互补原语以覆盖受限环境。
4.3 工程化思维:多原语链式组合、环境适配与利用可靠性设计
Dirty Frag的披露文档展示了高度的工程化思维:
• 多原语链式组合:不是追求单个“完美漏洞”,而是将两个有缺陷的原语拼接为通用武器。
• 环境适配:针对Ubuntu(AppArmor限制命名空间)与RHEL(可能允许命名空间)的不同默认配置,设计自适应利用路径。
• 可靠性设计:确定性逻辑漏洞确保利用成功率接近100%,且失败不引发系统崩溃,适合在实战环境中使用。
这种工程化思维标志着内核漏洞研究从“工匠手作”向“工业化生产”的转型——研究者像设计供应链一样设计攻击链,像管理库存一样管理原语组合。
5. 漏洞发现与分析工作的人机分工再论
5.1 范式转变:AI 辅助漏洞挖掘的能力爆发——仍以Theori / Xint Code 的 Copy Fail 扫描实践为例
Copy Fail的发现过程是一个人机协同漏洞挖掘的的范例样本。Taeyang Lee借助Xint Code平台,通过AI辅助扫描在Linux内核AF_ALG子系统中识别出Copy Fail漏洞。
AI在此过程中的核心价值在于问遍所有相关问题:
遍历所有子系统中可能的页缓存交互路径;
识别所有未执行COW检查的代码模式;
关联历史补丁(如Avoid skb_cow_data系列)与当前代码状态;
在人力不可行的时间尺度内完成跨版本、跨子系统的模式匹配。
5.2 机器智能的适用域:大规模模式识别、原语候选发现与代码路径关联
机器智能在漏洞发现中的适用域可明确界定:
| 适用域 | 机器能力 | 人类局限 |
| 大规模模式识别 | 可在数百万行代码中秒级匹配"未检查共享页即原地写入"模式 | 人力无法逐行审计内核所有子系统 |
| 原语候选发现 | 自动枚举所有可能提供页缓存写入的代码路径 | 人类易受认知偏差影响,遗漏非直觉路径 |
| 代码路径关联 | 自动关联2017年`Avoid skb_cow_data`提交与2026年`splice()`交互路径 | 人类难以跨越9年时间尺度建立因果链 |
| 历史漏洞复用 | 识别CVE-2022-27666与Dirty Frag漏洞来自同一模块 | 人类可能因子系统差异而忽视关联 |
5.3 人类研究员的核心价值:原语语义推理、链式组合创新与伦理判断
然而,机器智能的边界同样清晰。在Dirty Frag的发现中,Hyunwoo Kim展现了人类不可替代的三重价值:
第一,原语语义推理。机器可以识别"这里有一个写入操作",但只有人类能判断"这个写入操作是否构成了页缓存写入原语"、"写入的值是否可控"、"可控程度是否足以覆盖setuid二进制"。语义推理涉及对内核行为、加密协议、内存管理语义的深度理解,这是当前AI的弱项。
第二,链式组合创新。机器可以分别发现xfrm-ESP缺陷和RxRPC缺陷,但将两者识别为"可互补的原语对"、并设计链式利用逻辑,需要人类级别的创造性思维与系统级架构视野。
第三,伦理判断。负责任披露的边界、利用代码的公开时机、对关键基础设施的影响评估——这些涉及价值权衡的决策必须由人类做出。AI可以计算风险概率,但无法承担伦理责任。
5.4 人机协同的理想模型:“人类构造范式,机器狩猎原语”的分工边界
基于上述分析,我们再次强调,在此前关于Copy Fail分析中关于人机协同的的分工观点:
人类负责“问对问题”——构造范式;机器负责“问遍所有相关问题”——狩猎原语。
具体分工如下:
人类(安全研究员):承担原语语义验证、链式组合设计、利用可靠性工程、伦理判断与披露策略制定等认知密集型任务,将原语候选转化为实战能力。
机器(AI/自动化工具):承担原语候选发现、模式匹配、跨版本关联、历史漏洞比对等计算密集型任务,输出“原语候选清单”。
这一分工不是简单的“机器辅助人类”,而是“人机高速迭代传动”——机器扩展了人类可触及的原语空间,人类提升了机器发现的原语价值。
5.5 漏洞分析人才培养的启示:从“挖洞手”到“原语架构师”
Dirty Frag案例对安全人才培养提出深刻启示。传统人才培养模式聚焦于“挖洞”技能—— fuzzing、逆向、调试。但在人机协同时代,单一挖洞技能正在被机器部分替代。未来的核心能力应是原语架构师素养:
系统级视野:理解内核各子系统如何交互,识别跨子系统原语组合的可能性;
抽象思维能力:从具体漏洞中提取攻击原语,从原语层面设计利用框架;
人机协同能力:善用AI工具扩展狩猎范围,同时保持对AI输出的批判性验证;
工程化能力:将原语组合为可靠、通用、环境自适应的利用链。
5.6 对工具链建设的启示:原语识别、语义标注与链式组合推演的智能平台
工具链建设应从“单点漏洞扫描”进化为“攻击原语识别、语义标注与链式组合推演”的智能化支撑平台。具体而言:
原语识别引擎:不仅识别崩溃点,而是识别代码路径赋予的“原子能力”(读/写/执/降级);
语义标注系统:为每个候选原语标注其可控性、确定性、环境限制、所需特权;
链式组合推演:基于标注数据,自动推演多原语组合的可能性,输出“环境→原语→链式”的映射图谱;
人机交互界面:允许研究员对机器输出进行语义修正、补充领域知识、标记伦理约束。
6. 防御视角的原语对抗与架构反思
6.1 防御范式转换:从“修补 CVE”到“消除原语”的策略升级
Dirty Frag与Copy Fail的连续曝光,暴露了传统“修补CVE”防御范式的根本性局限:CVE是原语的实例化表现,修补一个CVE只是消除一个原语获取途径,而非消除原语本身。只要页缓存写入原语的内核基础条件存在(共享页可被原地写入且未强制COW),新的CVE就会在不同子系统中反复涌现。
防御范式必须升级:从“修补CVE”转向“消除原语”。具体而言,防御方应识别内核中所有可能提供页缓存写入原语的代码路径,并通过架构级改造(如强制COW、共享页标记隔离)消除该类原语的存在基础。
6.2 页缓存写入原语的缓解策略:COW 强制化、共享页标记与路径隔离
针对页缓存写入原语,可采取三层缓解策略:
第一层:COW强制化。在所有涉及外部数据(如splice()来源)的内核路径中,强制对共享页执行COW。Dirty Frag的上游修复补丁(commit f4c50a4034e6)即采用此思路:对从splice()来的外部共享frag打标记,在ESP输入路径识别并强制走COW。
第二层:共享页标记。引入SKBFL_SHARED_FRAG等标记位,明确标识skb frag是否来自外部共享页缓存,使后续所有原地操作路径(解密、解压缩、校验和计算)在执行前进行标记检查。
第三层:路径隔离。将涉及原地写操作的内核路径(如ESP解密、RxRPC解密)与可能接收外部页缓存页的路径(如splice())进行架构级隔离,确保两者不在同一skb上交汇。
6.3 内核安全架构演进:子系统间原语传播阻断与最小权限原则
Dirty Frag的跨子系统链式利用揭示了内核安全架构的一个深层问题:子系统间缺乏原语传播阻断机制。xfrm-ESP与RxRPC在代码层面完全独立,但攻击者通过页缓存这一共享资源将两者串联。防御架构应引入:
子系统间原语传播阻断:通过内存域隔离、引用权限细化,防止一个子系统的缺陷被用于放大另一个子系统的缺陷;
最小权限原则:默认禁用非必要子系统(如RxRPC),减少攻击面;
能力审计:对内核中所有“原地写”操作进行系统性审计,建立白名单机制。
6.4 对“执行体治理”理念的映射:运行对象层次的约束、审计与行为基线
安天提出的“执行体治理”理念强调:网络安全防御应回归运行对象层次,建立对“系统内哪些执行体正在执行”“ 新的执行体从何而来”“ 执行体应当如何被约束”的系统性回答。Dirty Frag案例从攻击侧验证了这一理念的必要性:
系统内哪些执行体正在执行:页缓存写入原语篡改的是setuid二进制在内存中的执行映像,防御方必须监控“执行体映像的完整性”而非仅“磁盘文件的完整性”;
新的执行体从何而来:通过splice()注入的页缓存页是外部来源,防御方应对“非文件系统直接加载的执行体页”进行标记与审计;
执行体应当如何约束:对setuid二进制等高风险执行体,应强制其在独立内存域中运行,禁止与其他子系统共享页缓存页。
7.结论与展望
7.1 攻击原语思维对漏洞研究的范式意义:从现象描述到能力抽象
Dirty Frag的发现过程证明,攻击原语思维是漏洞研究从“工匠时代”进入“人机协同时代”的关键认知升级。它要求研究者从“哪行代码错了”的现象描述,跃迁至“这段代码赋予了我什么原子能力”的能力抽象。在这一范式下,CVE不再是研究的终点,而是原语获取的副产品;漏洞不再是孤立的代码缺陷,而是可组合、可复用、可演进的能力单元。
7.2 人机分工的再平衡:安全研究者的核心能力重塑与平台建设
AI的爆发式增长正在重塑漏洞研究的人机分工。机器在“问遍所有相关问题”上的效率优势不可逆转,但人类在“问对问题”上的核心价值不可替代。未来的安全研究者必须重塑核心能力:从“挖洞手”进化为“原语架构师”,从“代码审计员”进化为“能力抽象师”,从“单兵作战”进化为“人机协同指挥官”。同时,安全机构必须建设支撑这一转型的智能化平台——原语识别、语义标注与链式组合推演的能力中心。
7.3 未来的威胁对抗和漏洞响应基本趋势:集约化分析平台与应急协调机制的融合
Dirty Frag的CVE编号存在约1-2天真空期与第三方提前公开事件,暴露了人工智能全面加速漏洞发现时代,漏洞响应体系的碎片化困境,为此安全机制也将重新校准。趋势:
大规模威胁和漏洞分析平台基础设施价值会凸显:基于规模化算力支撑的综合分析平台建设,运用通用+垂直模型,为研究者和防御者服务,支撑威胁样本分析、漏洞挖掘情报共享能力,已经成为新型的安全基础设施。而从人工智能+网络安全角度,这里远比防范“天网觉醒”更需要优先投入。
而传统应急协调机制不仅不应削弱,而且需要进一步强化,其必然从原有的事件触发、流程驱动、响应协同型机制,转型为为依托平台的公共安全服务机构。
预测性防御:基于攻击原语图谱,基于DevSecOps的视角和安全产品的防御点视角,对存在原语基础但尚未发现具体CVE的代码路径进行预加固,推动漏洞响应从“以知促防”向“未知先防”转变。
泛在的感知:越是在漏洞发现利用时间窗口被压缩的时代,安全检测感知能力就更需要泛在化,才能更大概率的感知到定向攻击活动。
结语
我们必须清醒认识到:漏洞不是一个对象客体,其是信息系统的一个自身属性。其在复杂性场景下必然存在,无法消亡。社会资源、数字演进速度和实践规律证明,也不具备将所有系统都转化为可形式化证明系统的资源条件(即使这样做也无法消亡攻击)。防御者对漏洞的有效目标立场,是使漏洞难以利用致效,而非幻想漏洞的穷尽和消亡,这是一个长期动态的过程。
防御者需要构建“盾立方”式的安全体系,收缩暴露面、识别所有的执行体、把控运行入口、切断漏洞利用链、拦截漏洞利用的后续植入、控制执行体运行的行为后果——都是必须持续进行的工作。攻击原语思维的引入,正是为了更精准地识别漏洞利用的能力基础,更科学地分配人机协同的智力资源,更有效地构建面向当下和未来风险的防御体系。
附录 A:Dirty Frag / Copy Fail / Dirty Pipe 攻击原语能力对比矩阵
| 对比维度 | Dirty Pipe(CVE-2022-0847) | Copy Fail(CVE-2026-31431) | Dirty Frag(CVE-2026-43284,CVE-2026-43500) |
| 核心子系统 | Pipe | AF_ALG / algif_aead | xfrm-ESP + RxRPC |
| 页缓存写入能力 | 通过管道拼接实现篡改 | 通过加密操作实现写入 | 双原语链式组合写入 |
| 写入大小 | 任意(管道写) | 4字节(加密尾部) | 4字节(ESP)+8字节(RxRPC) |
| 值可控性 | 直接可控 | 直接可控 | ESP直接可控 / RxRPC间接可控 |
| 确定性 | 逻辑漏洞,无需竞态 | 逻辑漏洞,无需竞态 | 逻辑漏洞,无需竞态 |
| 特权要求 | 无 | 无 | 无(RxRPC路径完全无特权) |
| 命名空间要求 | 无 | 无 | ESP需命名空间 / RxRPC无需 |
| 覆盖范围 | 主流发行版 | 主流发行版 | 全系列主流发行版 |
| 发现者 | Max Kellermann | Theori / Xint Code / Taeyang Lee | Hyunwoo Kim(@v4bel) |
| 标志性意义 | 开创页缓存篡改范式 | AI辅助发现,证明范式可复现 | 通用化、工程化、武器化 |
附录 B:Linux 内核页缓存写入原语的历史演进时间线
| 时间 | 事件 | 技术意义 |
| Jan-17 | Steffen Klassert提交`esp4/6: Avoid skb_cow_data whenever possible` | Dirty Frag xfrm-ESP原语的根因引入 |
| Feb-22 | Max Kellermann披露Dirty Pipe(CVE-2022-0847) | 首次证明页缓存可篡改,开创攻击范式 |
| Mar-22 | Steffen Klassert签署CVE-2022-27666修复补丁 | 首次意识到2017年优化的安全隐患 |
| Jun-23 | RxRPC相关commit引入(`2dc334f1a63a`等) | Dirty Frag RxRPC原语的根因引入 |
| Apr-26 | Theori/Xint Code披露Copy Fail(CVE-2026-31431) | AI辅助发现,证明页缓存写入范式可复现 |
| May-26 | Hyunwoo Kim披露Dirty Frag | 双原语链式组合,实现通用化提权框架 |